UWP_Teamwork(二)--Plan our final project-exReader(碎纸阅读器)
Focus
一款自动提取生难词的英文文章阅读器 – 让你再也不用边看文章边查词 ~
项目概述
应用功能
阅读英文文章
软件的初衷就是为了便捷英语学习者对英文阅读能力提升的学习。所以软件最基本的定位和 功能就是阅读器。用户可以在网上截取任意英文选段或者文章粘贴到阅读器里,软件提供舒 适的阅读体验。主要子功能有:
粘贴文本或者从本地导入.txt与.pdf格式的文件
修改阅读文本的背景颜色
修改文本的字体风格和颜色、大小
提取文章生难单词
软件最核心的功能是此部分。也是启发项目构思的功能。主要子功能有:
提取文章含有的相应阶层词汇(六级、考研、托福等),生成单词表
文章生难词高亮显示
自动生成生词本
便捷用户的后续复习与积累生难词汇,软件会自动将提取出的生难词加入生词本,用户可将 生词导出。
- 生词本导出
应用特色
不同难度阶层单词提取
本软件最大的特色,就是可以根据自身学习需要和能力水平提取出文章内的生难词。这对正在准备该阶层英语水平考试的用户很有帮助。例如:用户可以选择考研模式,文章会过滤掉低级词汇,自动提取出考研词汇大纲要求的词汇,直面需求。当然也可以自定义选择多余的阶层词汇提取,此时用户还可以将托福词汇也勾选上,选择多个阶层的词汇库,词汇列表会将生词分类。
文章标注生词高亮
在提取完相应模块的单词后,软件会将这些单词在文中标注高亮。不同模块词库对应的高亮颜色不同。
生词本单词发音
对提取出的单词,软件不仅会显示单词释义,用户还可以点击单词的音标对其进行发音。
优质文章源/网站的推荐
软件会在导航栏里面整合静态的推荐链接
生词本单词的查询
项目结构
页面架构
主页面效果图:
此图为软件的主页面效果图。主要分为三大板块。
第一板块是NavigationView导航栏。会隐藏在界面最右端。呼出时会覆盖在与阅读页上。内包含了用户的资源信息:生词本、已阅读的文章、设置等。
第二板块是主题板块,阅读页面。分为三个子版块。第一板块是title,显示为文章的标题;第二子版块是工具栏,对文章的页面和字体进行设置;第三子板块是文章页面。
第三板块是提词列表板块。分为两个子版块。第一个子版块是提词库模式的选择。有6个词库模式。第二子版块是实时提取出的生难词列表,并根据词库模式分栏归类。
页面具体设计
阅读页面

此页面是文章阅读界面,是文章第一块主页面。顶部可显示目前文章标题(可自定义名称),主体部分是文章阅读页面,正文上方有Tool bar,对文章进行一些效果编辑。支持背景色、字体风格、字体大小等其他待添加功能。左边是文章导入按钮,可进行本地txt文件导入。后续可能会加上pdf。
提词列表页面

此页面是提词列表页面,也是软件的第二块主页面。此页面会根据用户对提词词库模式的选取,在文章中检索相应的词库,然后归类添加显示到实时提词列表内,用户在阅读文章时,可以快速的浏览到自己可能不认识的生词,然后进行连续的阅读体验。用户也可以对提取出的词汇右键移除,在保存列表后,这些生难词会自动加入生词本。
导航栏页面

导航栏页面主要是用户的资源信息。 主要有生词本、已阅读的文章、和文章源的推荐。也可以增加用户词库选择的默认设置。
生词本页面
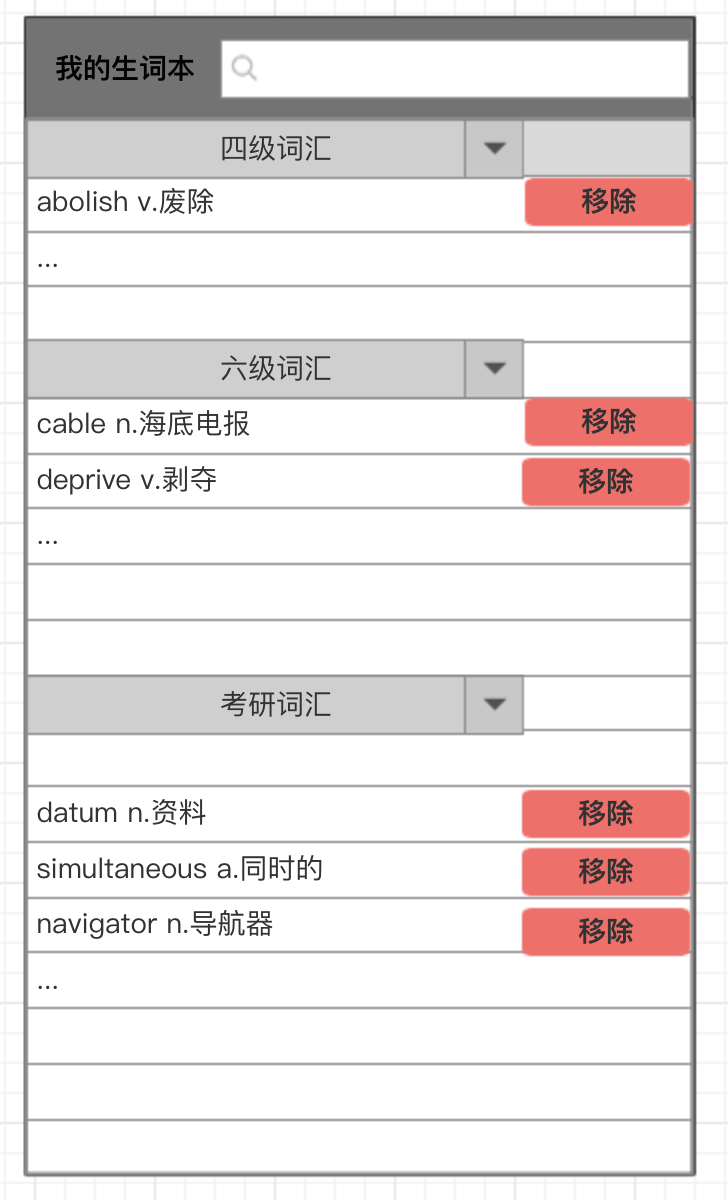
生词本页面是最近文章提词结果的自动保存,根据词库自动归类。用户可以在顶部搜索栏快速查询到自己收录的生难词。另外,用户在复习掌握生词后,可以对生词本里的单词进行移除,清理自己的生词本。
交互细节
细节一
多模块选择。
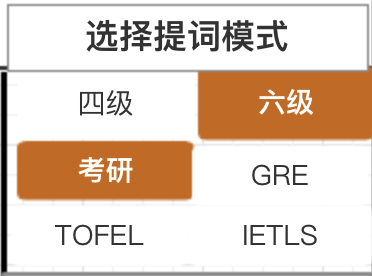
此处的模块,放置了多个选择按钮,他们相互独立。用户可以选择多个模式,交付给系统进行提词。
细节二
右键移除。
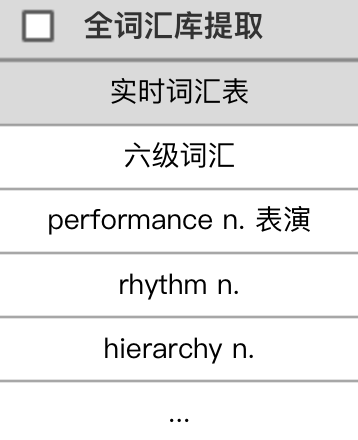
提取的词如果包含了用户已掌握的单词,用户可以右键ListBox Item,然后从提词表中移除该词汇。
细节三
词汇不同颜色高亮。

词汇的高亮。不同阶层的词汇库对应不同颜色的高亮。
提取的词如果包含了用户已掌握的单词,用户可以右键ListBox Item,然后从提词表中移除该词汇。
相关技术
文章提词功能
- 将一个文章粘贴到文章版中,如果文章中出现了用户没有学过的生词,程序可以将它们提取出来,并标注这是6级词汇、考研词汇或是超纲词汇。我们正在考虑是将生词高亮还是用一个ListBox展示。
- 为了做到这一点,我们需要几个常用词库,以及能够对文章单词和词库单词进行比对的数据结构和算法。
- http://vdisk.weibo.com/s/D78tbL-aMdF-J
- 首先我们需要有个词库,这个网站给了我们考研词库。
- http://vdisk.weibo.com/s/BHFIjmuCDwpsu
- 这里有六级词汇,同样是直接可下载。这些文件处理成我们需要的数据结构即可。
- https://blog.csdn.net/silangquan/article/details/51106968
- 这个网站提供了C#常用容器的用法。我们考虑用HashSet或HashMap存储词库,这样可以非常迅速地知道某个词属于或不属于哪个词库。
- http://vdisk.weibo.com/s/D78tbL-aMdF-J
已学单词库
程序将会内置一个已学单词库,对于用户已经学过的单词,文章提词将不会再对其显示。文章提词的结果经过用户标注后,会进入已学单词库,并存储起来。
为了做到这一点,我们需要把已学单词库保存成文件,要使用文件操作。
https://www.cnblogs.com/bingxing/p/7147562.html
- 这个网站说明了怎么用FileStream进行读写文件,这样我们就可以像C++的cin和cout一样处理文件了,新单词直接入库。
https://blog.csdn.net/u013569749/article/details/56494880
- 思路还是Stream
高频词功能
- 这是我们考虑做的扩展功能,在前面的功能做好之后,若有余力,我们就给单词添加高频词属性,这样就可以在文章提词的时候给用户标注高频词,重点学习。
- 为了做到这一点,要给单词添加一个新属性,所以我们可以考虑用HashMap<String, ArrayList
>。然而我们发现这是一个无比愚蠢的想法。 - https://www.cnblogs.com/icebutterfly/p/7850689.html
- https://www.cnblogs.com/luxiaoxun/p/3784729.html
- 稍有常识的人都会看出,如果功能继续增多,这个使用HashMap<String, ArrayList<HashSet<……>>>来扩展功能的团队,难道能够应付得了吗?
- SQL关系数据库可以处理一个事物的多个属性。我们可以用SQLite来存储各种词库,遇到单词对比或者提词就可以使用关系数据库强大的各种运算来解决,连最简单的HashSet
都不需要了。SQL对于各种查询都有完备的解决方案,而且我们的功能都可以用关系运算来表示;相比之下,自己写HashMap的嵌套结构,写的时候很复杂,扩展的时候更要全部都要改。
- 所以我们决定,推翻前面的全部设计,从一开始就采用SQLite做单词库,已学词库。
采访视频
http://player.bilibili.com/player.html?aid=21912325&cid=36183328&page=1
根据采访结果,我们更新后的设计:
新增功能一 :全文翻译
受访者有翻译全文的请求。我们会考虑将此功能加入。
新增功能二 :词汇发音
我们会在提取出的单词加入音标属性,通过调用第三方url实现发音
新增功能三 :优质文章源(英文网站)推荐
在导航菜单栏内加入优质的考研高频文章取处的网站
修改功能一 :对提取出的单词编辑
由于用户自己掌握的词和提取出的大纲词汇肯定有重叠的地方,在采访后,我们确实收到了一位受访者这样的意见。用户可以删除默认提取出的单词中自己已掌握的词,减少干扰,也抹去了导入生词本的脏数据。
修改功能二 :对生词本编辑
用户在对生词本内单词复习后,可以编辑删除已掌握的单词,清理生词本。
附:软件名由来:
英文名:ex-取自单词‘提取’extract前两个字母;e又为English首字母,寓意英文阅读器。
中文名:寓意来源于碎纸机。软件功能与碎纸机“类似”,即导入一篇文章,文章碾碎为零散的单词。
Collaborators: 汤浩、李京懋、王云昊、侯平月、三位可爱的受访者
⬅️ Go back